
From Content-based to Graph-based: the Future of Recommender Systems

Abstract
A recommender system (or recommendation engine) refers to a piece of intelligent technology that provides users with suggestions of products and content which they might like.
Recommender systems have shaped the face of online shopping, social media and video streaming over the last couple of decades. They are one of the technologies that have particularly benefitted from the big data revolution but, at the same time, have shaped the demand for data and technologies such as cloud computing and storage. Nowadays, a significant part of profits from e-commerce businesses come as the result of these new technologies.
Recommender systems continue to evolve as new methods and algorithms are discovered, and more data is available, both in terms of volume and variety. In this paper we present an overview of the history of recommender systems, starting from precursors of recommendation engines, all the way to modern deep learning systems.
We conclude with an exposition of graph recommender systems, which represent the latest evolution of recommendation engines. Furthermore, we describe and expand upon Ocula, a graph-based recommender system that can combine the best elements of hybrid approaches with knowledge-based approaches in order to give very accurate recommendations, by utilising expert knowledge.
General Overview of Recommender Systems
If you watch movies on platforms like Netflix or videos on networks like YouTube, you will have encountered recommender systems. The same applies when shopping on Amazon and many other popular websites. They are a hugely significant feature of the internet, and their use is becoming more and more important.
Why? Let’s look at some figures. The recommendations made by Netflix account for about 80 percent of the movies that are watched. On YouTube, 60 percent of homepage clicks are the result of recommendations. For the e-commerce giant Amazon, 35 percent of its sales are the result of recommendations.
Recommender systems are a fascinating field because they combine different types of technologies, from data engineering to different types of machine learning. The growth of this field has actively contributed to the improvement of artificial intelligence, e-commerce, and other areas, such as big data technologies and online streaming.

Figure 1. Amazon’s recommender system in action
What Are Recommender Systems?
Recommender systems are a type of information filtering system, closely related to different fields of data mining such as information retrieval and supervised learning.
The objective is to predict user preferences and then make recommendations. This could be products to buy, movies to watch, articles to read, or music to listen to. They are used in everything from e-commerce stores to streaming platforms to advertising tools. They also have a long history in social media.
They are different from search algorithms, as search algorithms return results you have asked for. A recommender system, on the other hand, will show you items you are not looking for directly, but might be interested in. Hence, recommender systems need to find a careful balance between exploration and exploitation. That is, make sure that they show relevant items to the user, while also trying to predict completely new items that the user is expected to like.
The History of Recommender Systems
The history of recommender systems goes back to the 1970s. The earliest systems didn’t make recommendations as such, but instead, categorized articles and other text-based content to make it easier for users to find what they were interested in.
The first solution to actually make recommendations was Grundy. It was a computer-based librarian that went live in 1979. It put users into pre-set sub-groups based on expressed preferences. However, it could not make individual recommendations, as each person in a sub-group received the same list of recommended books.
The next big advances came in the 1990s with the development of systems like the GroupLens Recommender System. It could make recommendations to Usenet users on articles they might like to read.
Early incarnations of the Yahoo! search engine are also worth a mention, as it was built to make it easier for people to find things on the internet that interested them. However, Amazon led the way in the late 1990s with the development of recommender systems that bear similarities to those in use today.
Roll forward to today, and the Amazon recommender system is familiar to millions of people all over the world. It basically means that every visitor to Amazon sees a unique homepage that is tailored to them based on their preferences (purchases, search history, product ratings, etc.) and the preferences of other visitors who have made similar purchases.
That said, the Amazon recommender system isn’t the only one encountered by millions of people on a daily basis. Another example is Netflix, which is important to mention in the context of the history of recommender systems because of the Netflix Prize.
The Netflix Prize put a major spotlight on recommender systems in the mid-to-late 2000s. It ran from 2006 to 2009 and was a competition sponsored by the company with a prize worth $1m.
To win the prize, teams had to produce a recommender system that was at least 10 percent more accurate than Netflix’s existing recommender system at the time. The prize was won in 2009 by the team BellKor’s Pragmatic Chaos. It was made up of scientists from Austria and AT&T Labs in the US.

Figure 2. Pragmatic Chaos win the Netflix prize. Source:
The Main Types of Recommender Systems
Content-Based Recommender Systems
Content-based filtering is the simplest recommendation technique. It’s so simple that pretty much anyone could implement it with a few lines of Python code.
Content-based recommender systems analyse user preferences to match them with item data. For example, an e-commerce store recommender system that is content based would look at a user’s search history, items they have bought, and items they have rated. It will then match these preferences to items in its inventory.
The way this happens is by encoding the features of each item as a vector, and then using simple similarity measures such as cosine similarity or the Euclidean distance, to measure how aligned two vectors are with each other.
The main benefit of those systems is that they allow the explicit modelling of domain knowledge. The system designer can use knowledge about product categories, user preferences, etc. Also, this type of recommender system can beat the cold start problem since it can work even at the absence of data. Other types of recommender systems are data-hungry, and a decent user base before they can make good recommendations.
There are limitations with this type of recommender system however, as it is only good at making recommendations based on one type of content. So, in the example above, a content-based recommender system used in an e-commerce store would be limited in its ability to make recommendations on anything other than the products in its dataset.
Collaborative Filtering Recommender Systems
Unlike content-based recommender systems, collaborative filtering recommender systems don’t need to know anything about the items they are recommending. Instead, they make recommendations based on the similarity between users or items.
So, for example, if a collaborative filtering recommender system knows that user A and user B like similar movies based on historical information, it will assume they will also like similar movies in the future. As a result, if user A watches and likes a movie, the system will recommend it to user B.
That is a very basic example, but it demonstrates the fact that the system didn’t need to know anything about the movie that user A watched to make the recommendation. Instead, it works by making connections between different users (or items). This means content filtering recommender systems are effective across different item types, as well as being capable of making recommendations on complex items.
The major disadvantage is that it needs data upfront to be able to make recommendations. Hence, the cold start problem is a clear challenge for those systems. So, in the example above, if a new user joins the platform, a content filtering recommender system would not initially know if they like or dislike the same movies as users A and B.
Collaborative filtering is based on simple principles, but it is very adaptable, and it has been one of the techniques that has revolutionised the field of recommendation. Even more advanced methods like deep learning recommender systems still apply some form of collaborative filtering at some point within the network
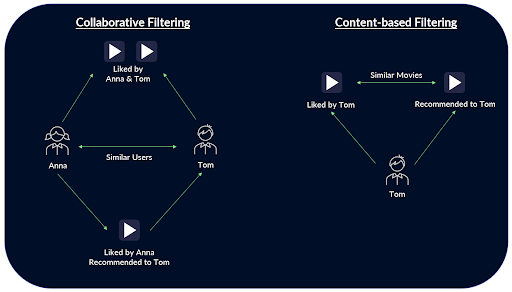
Figure 3. Differences between collaborative and content based filtering. Source:
Deep Learning-Based Recommender Systems
Deep learning-based recommender systems are used in some of the most popular platforms on the internet, including YouTube and Amazon. The global e-commerce platform Alibaba is also a leading innovator.
Deep learning-based recommender systems are different from traditional systems in the sense that they take a hybrid approach that allows them to approach data from different angles. Deep learning-based recommender systems can use much more complex datasets to enable them to make recommendations based on rich information at multiple levels. They enable the combination of architectures and methods which usually were implemented separately, such as collaborative filtering, embeddings, and supervised learning. A piece of pioneering work in this area was Google’s Wide and Deep architecture in 2016, which has now been advanced in many different ways.

Figure 4. Google’s Wide and Deep architecture. Source:
The flexibility that neural networks offer mean that they have fewer limitations compared to traditional methods and allow the combination of different types of information. For example, a deep learning recommender system could make recommendations based on visual similarities between products, product price ranges, the type of engagement, the user’s search query, or even features such as images. The obvious drawback of this approach is that it is data-hungry and processing intensive, as it is often the case for deep learning.
What are Graph Learning-Based Recommender Systems?
Graph theory is a domain of mathematics that deals with the study of graphs and networks. In the last few decades, graphs and networks have become more popular in the domains of computer science and artificial intelligence. This has happened as the result of social networks where network theory can help uncover all kinds of insights as well as graph databases such as neo4j which facilitate operations over graph data. It’s no coincidence that the API of Facebook is called Graph API.

Figure 5. Visualisation of a user’s Facebook friends, clustered through the use of network analysis. Source: http://touchgraph.com
Graph learning-based recommender systems use graph learning techniques to analyse item characteristics and user preferences. They are a type of deep learning-based recommender system, which uses techniques and methods from graph theory and network theory. Therefore, they use rich and complex information from different sources to make recommendations.
For example, graph learning-based recommender systems can combine social information, item attributes and ontologies in a natural way, which doesn’t happen easily with other types of models. They can be used for segmenting nodes (like if Figure 5) or make other types of predictions around nodes and edges, such as predicting whether certain molecules are toxic or good candidates for a pharmaceutical drug.
Crucially graph-based recommended systems can make both explicit and implicit connections between important elements to make more detailed and accurate recommendations to users. As a result, they are an exciting subset of recommender systems that will push the technology forward.
The Application of Recommender Systems at Ocula
Ocula offers this new paradigm in graph recommender systems that combines techniques from traditional network analysis, with machine learning.
The system is powered by a knowledge graph. This is a carefully crafted network, which represents knowledge of a domain. The knowledge graph combines different technologies together, from traditional SQL to graph theory.

Figure 6. Example of a knowledge graph representing knowledge about purchases of collectible stamps
The role of the knowledge graph is to encode knowledge about a particular domain. For example, Figure 6 demonstrates a knowledge graph that represents knowledge about how stamp collectors will purchase a stamp. The recommender system is able to traverse this network from any node to any other in order to identify similarities between users and products and suggest new stamps to the users.
There are many benefits to using such a system:
It allows encoding expertise in much a better way that a content-based filtering system can do
It can work as a hybrid recommender since each node can utilise different machine learning models to extract additional information for the recommender
It is significantly faster, from a data engineering perspective, and more efficient than a tabular approach
Through our knowledge graph clients can start to deliver relevant recommendations to each of their customers, even if they don’t have a huge amount of data available. The primary results are an uplift in customer satisfaction and significant sales uplift. A secondary benefit is that the domain knowledge-based approach that Ocula follows can also guide the data strategy of an organisation, informing how to best shape its data function. Therefore, it presents a better choice than some of the other approaches that have been historically followed in the recommendation domain.
Related Posts


